Hardik Goel
Home
About Me
Projects
Research
Extracting data from HackerNews using Firebase API in Python
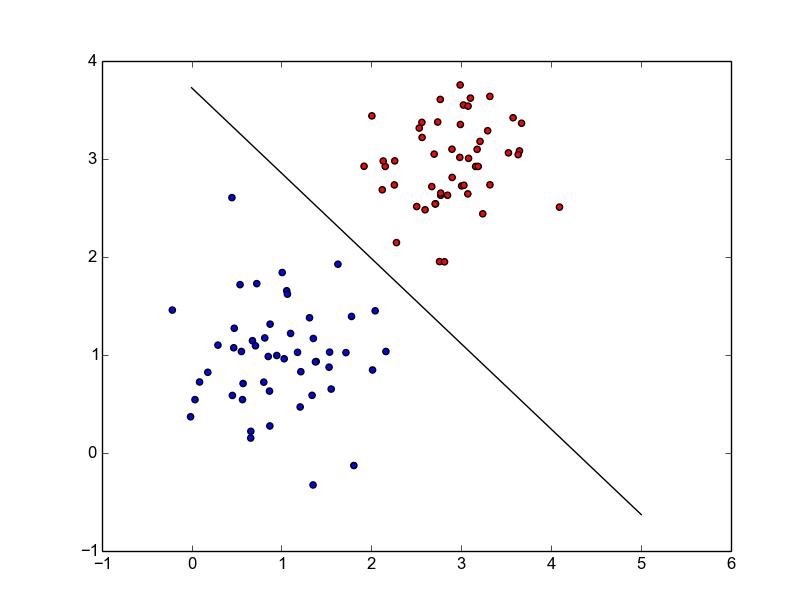
Implementing and Visualizing SVM in Python with CVXOPT
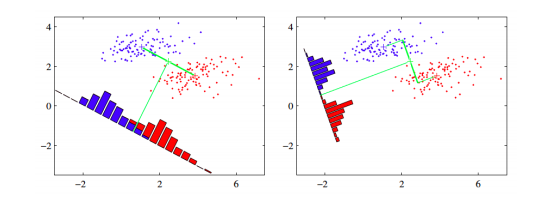
Implementing Fisher’s LDA from scratch in Python
Building autoencoders in Lasagne
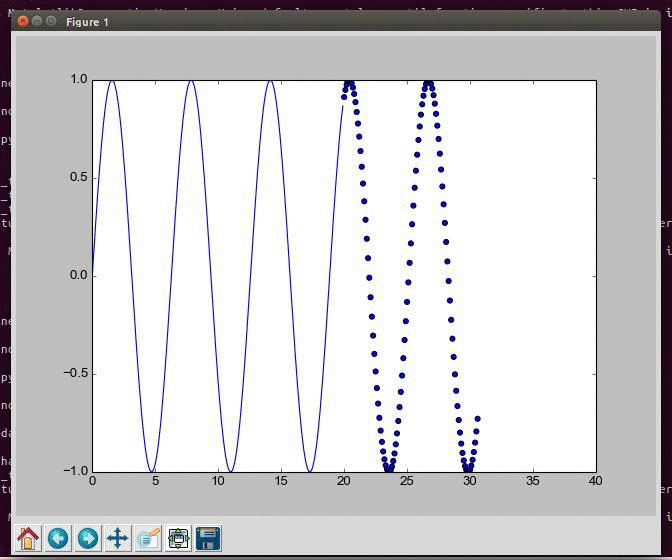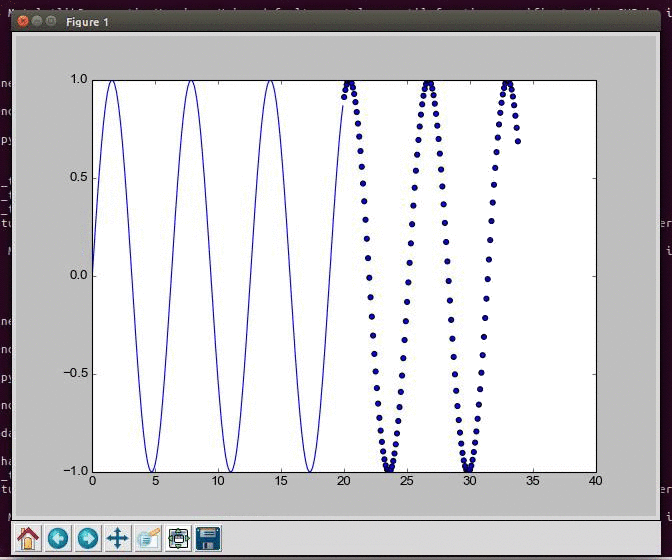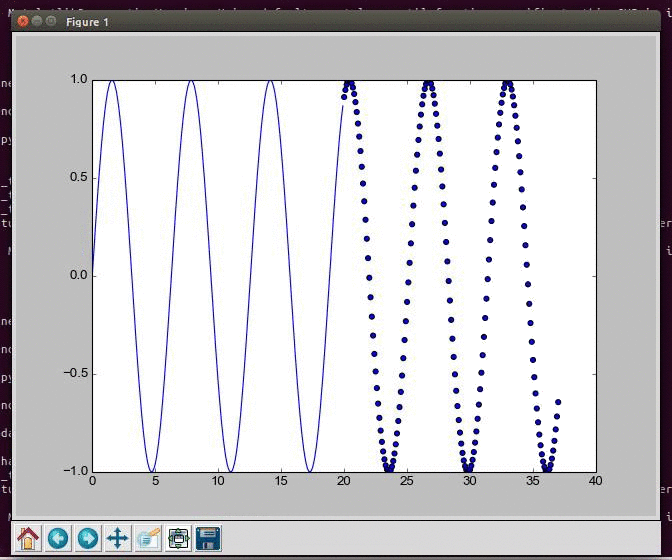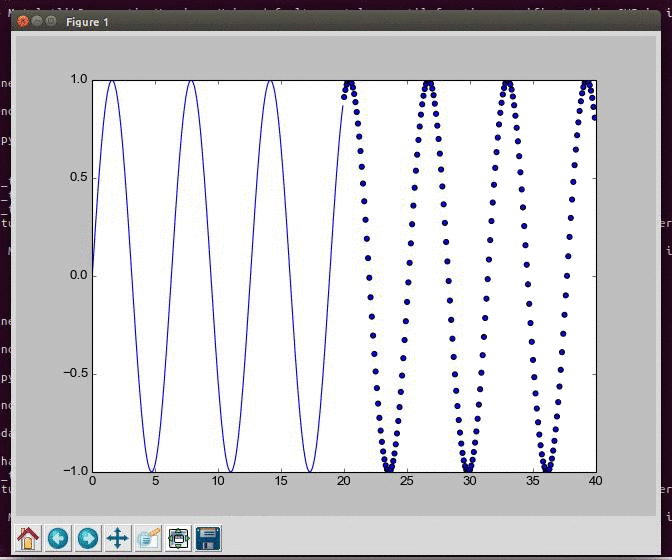
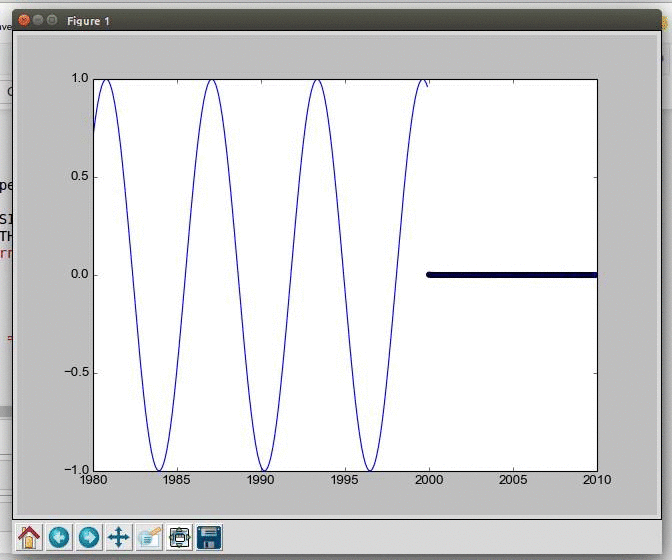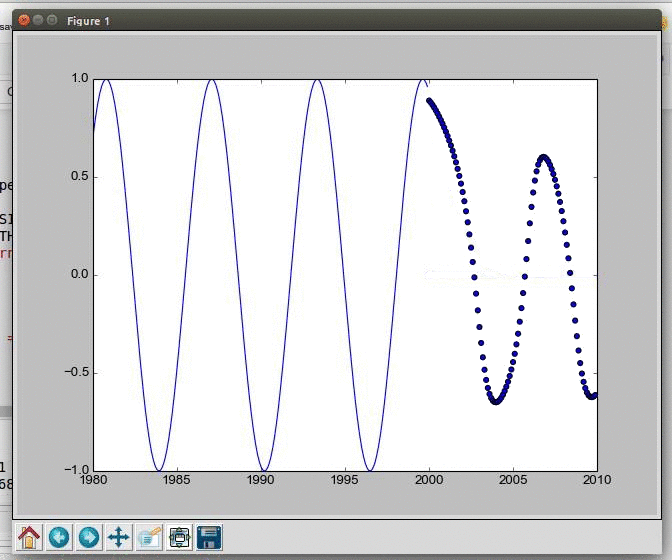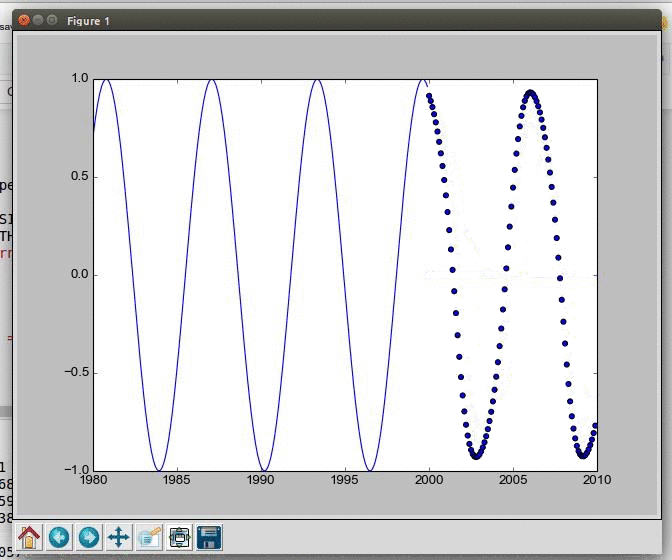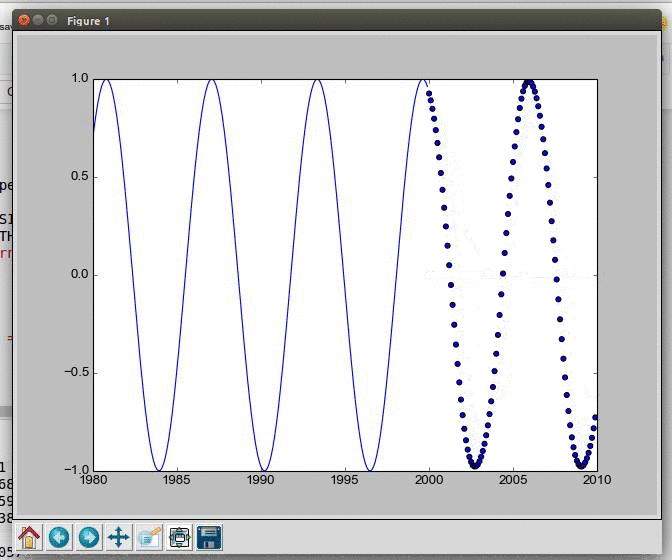
Generating and visualizing data from a sine wave in Python
Learning to predict a mathematical function using LSTM
Older
Newer